
¡Saludos, colegas Ingenieros, Licenciados y Docentes tecnológicos, y demás jovenes Estudiantes y Aprendices de las artes (cuasi) mágicas de la Computación y la Informática!
Ing. Informático y Docente TI: Jose Albert
En esta oportunidad, les traigo un genial Glosario de Inteligencia Artificial, debido a que como es lógico y razonable, para dominar un tema cualquiera, y más uno tan moderno, complejo y en pleno crecimiento y evolución como este, nada mejor que tratar de conocer, entender y dominar la jerga (términos y conceptos) relacionados con el mismo.
Y si de entrada eres de los que aún no tiene en claro que es la Inteligencia Artificial (IA), de inmediato es importante que sepas que Ciencia y Tecnología se define de forma breve y sencilla como «el campo de la informática dedicado a crear sistemas o máquinas capaces de realizar tareas que requieren inteligencia humana». Por ende, su objetivo fundamental es simular procesos de la inteligencia humana, como el aprendizaje, el razonamiento y la adaptación, a través de programas de cómputo inteligentes.

Además, como dato curioso, es importante conocer que, el término «Inteligencia Artificial» fue acuñado oficialmente en 1956 por John McCarthy. Mientras que, hoy en día, la relevancia de la IA es innegable en muchas de las esferas del hacer humano. Ya que, la misma ha impulsado avances revolucionarios en campos como la medicina, las finanzas, el entretenimiento, el transporte y la educación, transformando radicalmente la forma en que interactuamos con la tecnología y tomamos decisiones o aprendemos y enseñamos conocimientos y nuestra cultura. Y todo esto, gracias a que la IA opera poniendo una vasta colección de datos a través de algoritmos (conjuntos de instrucciones) para crear modelos que automatizan tareas que típicamente requerirían tiempo e inteligencia humana.
Siendo un buen ejemplo dentro del ámbito laboral y profesional, más específicamente en la Educación, comprender la IA es crucial. Ya que, el uso de la IA en la educación juega roles fundamentales, como el de Tutor inteligente, Herramienta de aprendizaje y enseñanza o Asesor en la formulación de políticas educativas. Por ende, este conocimiento es vital para fomentar la alfabetización en IA (la capacidad de usar esta tecnología de manera efectiva y ética), lo cual es necesario para que los Docentes y Estudiantes se desarrollen plenamente en el mundo actual y aumenten sus habilidades de pensamiento crítico. Por lo que aprender a desarrollar Prompts, en general, y sobre todo, con un enfoque educativo es algo esencial, a la hora de aprender y enseñar, o crear contenido pedagogico y educativo.
Así que, sin más que agregar, y teniendo en cuenta que, a medida que el «Léxico de la IA evoluciona y crece», te presentamos los términos y conceptos fundamentales para dominar este campo dinámico y en constante cambio.

Como Docente de Educación Media (Bachillerato) e Ingeniero en Informática, he diseñado este contenido utilitario como un punto centralizado de apoyo que sirva como una excelente compilación de términos y conceptos modernos e idóneos para el aprendizaje sobre todo aquello que hay que aprender y enseñar sobre el ámbito tecnológico de la Inteligencia Artificial. Ingeniero en Informática + Docente y Tutor CBIT: José Albert
Podcast IA introductorio
Video IA introductorio
Glosario de Inteligencia Artificial:
Ajuste de instrucciones
El ajuste de instrucciones es un enfoque donde un modelo pre-entrenado se adapta para realizar tareas específicas proporcionando un conjunto de pautas o directivas que describen la operación deseada.
Ajuste de modelos
El ajuste del modelo consiste en ajustar los hiperparámetros de un modelo de inteligencia artificial para optimizar su rendimiento. Este proceso implica probar diferentes combinaciones de hiperparámetros (como la velocidad de aprendizaje o la profundidad de capa) para encontrar las que ofrecen los mejores resultados en un conjunto de datos determinado.
Ajuste fino
El proceso de adaptar un modelo pre-entrenado a una tarea específica entrenándolo en un conjunto de datos más pequeño. Por ejemplo, un modelo de clasificación de imágenes entrenado en todas las fotos de intersecciones puede ser perfeccionado para detectar cuando un coche se pasa un semáforo en rojo.

Alfabetización en IA
Es la capacidad de comprender, interactuar y utilizar IA de manera efectiva y ética dentro de una amplia gama de contextos socioculturales. Esto implica tener un conocimiento sobre su funcionamiento y principios. Se podría decir que es el conjunto de competencias que permiten evaluar, comunicar y colaborar de forma efectiva y crítica con esta tecnología.
1. Algoritmo
Una serie de pasos repetibles para llevar a cabo cierto tipo de tarea con datos. Al estudiar Ciencia de Datos debemos conocer los diferentes algoritmos y sus respectivas ventajas y desventajas. El término proviene del nombre del matemático persa Muhammad ibn Musa al-Khwarizmi (alrededor del año 820), a quien debemos la introducción de la numeración decimal en Occidente. En la actualidad, designa una serie de instrucciones que deben ser ejecutadas en forma automática por un ordenador. Los algoritmos se aplican en todos los ámbitos, desde las consultas a través de dispositivos de búsqueda y la selección de información sugerida a los internautas, hasta los mercados financieros.
2. Alucinación
La alucinación se refiere a una situación en la que un sistema de IA, especialmente en aquellos casos en los que se encarga del procesamiento del lenguaje natural, comienza a generar resultados que pueden ser irrelevantes, sin sentido o incorrectos basados en la entrada proporcionada. Frecuentemente, esto ocurre cuando el sistema de IA no está seguro del contexto, depende demasiado de sus datos de entrenamiento o carece de una comprensión adecuada del tema que se le presenta.
3. Agente de IA
Un agente de IA es un programa de IA autónomo: puede realizar tareas y lograr objetivos en nombre de un usuario o de otro sistema sin intervención humana, diseñando su propio flujo de trabajo y utilizando las herramientas disponibles (otras aplicaciones o servicios). La IA agéntica es un sistema de múltiples agentes de IA, cuyos esfuerzos se coordinan u orquestan para realizar una tarea más compleja o alcanzar un objetivo mayor que el que podría lograr cualquier agente individual del sistema.
A diferencia de los chatbots y otros modelos de IA que operan dentro de restricciones predefinidas y requieren intervención humana, los agentes de IA y la IA agéntica exhiben autonomía, un comportamiento orientado a objetivos y adaptabilidad a circunstancias cambiantes. Los términos «agente» y «agéntico» se refieren a la agencia de estos modelos, o su capacidad para actuar de forma independiente y decidida.
Una forma de pensar en los agentes de IA es como el siguiente paso natural después de la IA generativa. Los modelos de IA generativa se centran en la creación de contenidos basados en patrones aprendidos; los agentes utilizan ese contenido para interactuar entre sí y con otras herramientas para tomar decisiones, resolver problemas y completar tareas.
4. Agrupación
La agrupación en clústeres es un método de aprendizaje no supervisado que consiste en agrupar datos similares en conjuntos denominados «clústeres». A diferencia de la clasificación, no hay etiquetas predefinidas. El modelo descubre similitudes en los datos para crear estos grupos, que se utilizan para el análisis del mercado o la segmentación de clientes, por ejemplo.
5. Amplificación de la inteligencia
La amplificación de la inteligencia (Intelligence Augmentation en inglés) o IA aumentada se centra en el desarrollo de tecnología para mejorar las capacidades cognitivas de los seres humanos, sin buscar su reemplazo.
6. Analíticas de aprendizaje
En educación, las analíticas de aprendizaje (learning analytics en inglés) es un campo emergente en la educación de carácter multidisciplinario, ya que integra informática, ciencias de la educación, estadística, minería de datos, pedagogía y ciencias de la conducta. En otras palabras, es el empleo de los datos para comprender y mejorar los procesos de enseñanza-aprendizaje. Entre sus objetivos se encuentran los siguientes: apoyar las estrategias de instrucción, identificar estudiantes de riesgo para brindar intervenciones efectivas, mejorar las experiencias de aprendizaje mediante el seguimiento de actividades y de retroalimentación, etcétera. Se utiliza en la realidad virtual (RV) y la realidad aumentada (RA), en asistentes inteligentes, entre otros.
7. Anclaje
El anclaje es el proceso de fijar sistemas de IA en experiencias, conocimientos o datos del mundo real. El objetivo es mejorar la comprensión del mundo por parte de la IA, para que pueda interpretar y responder efectivamente a las entradas, consultas y tareas de los usuarios. El anclaje ayuda a que los sistemas de IA sean más conscientes del contexto, permitiéndoles proporcionar respuestas o acciones más adecuadas, relacionables y relevantes.
8. Anotación de datos
La anotación de datos consiste en agregar etiquetas o descripciones específicas a los datos sin procesar (imágenes, texto, vídeos, etc.) para que los algoritmos de IA los entiendan. Esto permite entrenar los modelos de aprendizaje automático para reconocer objetos, acciones o conceptos en estos datos.
9. Apilamiento
El apilamiento es una técnica en IA que combina múltiples algoritmos para mejorar el rendimiento general. Al combinar las fortalezas de varios modelos de IA, el apilamiento compensa las debilidades de cada modelo y logra una salida más precisa y robusta en diversas aplicaciones, como el reconocimiento de imágenes y el procesamiento del lenguaje natural.
10. Aprendizaje adaptativo
El aprendizaje adaptativo (adaptive learning) emplea la instrucción basada en datos para ajustar las experiencias de aprendizaje de cada estudiante (ya sea en términos de dificultad, ritmo, etc.). Este tipo de aprendizaje rastrea datos diversos, tales como el progreso, la participación y el desempeño. Con esta información se pueden diseñar e implementar experiencias de aprendizaje personalizadas.
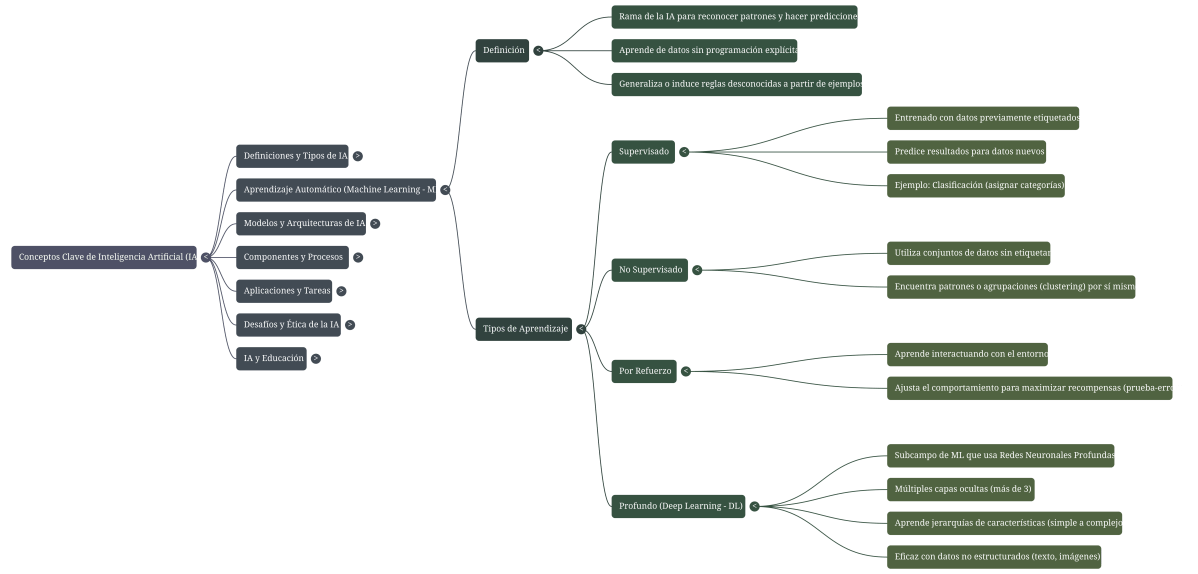
11. Aprendizaje Automático (Machine Learning)
Un subcampo de la IA que abarca el desarrollo de algoritmos y modelos estadísticos que permiten a las máquinas mejorar su rendimiento con la experiencia. Un ejemplo sería un algoritmo de aprendizaje automático que pudiera predecir la probabilidad de pérdida de los clientes basándose en su comportamiento pasado. Gracias a un programa de aprendizaje automático, la máquina aprende a resolver problemas a partir de ejemplos: puede así comparar y clasificar datos e incluso reconocer formas complejas. Antes de la llegada en 2010 del aprendizaje profundo, este tipo de programa era supervisado por seres humanos, ya que debía señalarse explícitamente cada imagen que contuviera un rostro humano, una cabeza de gato, etc. para que la máquina pudiera realizar la operación de reconocimiento solicitada.
12. Aprendizaje colectivo
El aprendizaje colectivo es un enfoque de entrenamiento de IA que aprovecha habilidades y conocimientos diversos a través de múltiples modelos para lograr una inteligencia más poderosa y robusta.
13. Aprendizaje de disparo cero o entrenamiento cero
El aprendizaje de entrenamiento cero es una técnica en la que un modelo de aprendizaje automático puede reconocer y clasificar nuevos conceptos sin ningún ejemplo etiquetado.
14. Aprendizaje multitarea
El aprendizaje multitarea es un método en el que un modelo de inteligencia artificial se entrena simultáneamente en varias tareas relacionadas. Esto permite que el modelo aprenda de manera más eficaz al compartir conocimientos entre las tareas, lo que mejora su rendimiento general en toda la gama de problemas a resolver.
15. Aprendizaje profundo (Deep Learning)
Un subcampo del aprendizaje automático (machine learning) que utiliza redes neuronales con múltiples capas para aprender de los datos, es decir, que utiliza distintas estructuras de redes neuronales para lograr el aprendizaje de sucesivas capas de representaciones cada vez más significativas de los datos. Un ejemplo sería, en este caso, un modelo de aprendizaje profundo que pudiera reconocer objetos en una imagen, procesándola a través de múltiples capas de redes neuronales. Y esto lo hace, actualmente el campo con más popularidad dentro de la Inteligencia Artificial. Nacido de la combinación de los algoritmos de aprendizaje automático con las redes neuronales formales y con el uso de los macrodatos, el deep learning revolucionó la inteligencia artificial. Tiene innumerables aplicaciones: motores de búsqueda, diagnóstico médico, vehículos autónomos, etc. Por ejemplo: En 2015, el ordenador AlphaGo aprendió a ganarle a los humanos en el juego del GO gracias al deep learning.
16. Aprendizaje supervisado
En Machine Learning el aprendizaje supervisado es una técnica para deducir una función a partir de datos de entrenamiento. Los datos de entrenamiento consisten de pares de objetos (normalmente vectores): un componente del par son los datos de entrada y el otro, los resultados deseados, es decir, los resultados a los que debe arribar el modelo.
17. Aprendizaje no supervisado
El aprendizaje no supervisado es un método de Machine Learning en donde el modelo es ajustado a las observaciones. En este caso el algoritmo es entrenado usando un conjuntos de datos que no tiene ninguna etiqueta; nunca se le dice lo que representan los datos. La idea es que el algoritmo pueda encontrar por si solo patrones que ayuden a entender los datos.
18. Aprendizaje por refuerzo
En los problemas de aprendizaje por refuerzo, el algoritmo aprende observando el mundo que le rodea. Su información de entrada es el feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende en base a prueba-error.
19. Aprendizaje potenciado
Un tipo de aprendizaje automático en el que un modelo aprende a tomar decisiones interactuando con su entorno y recibiendo retroalimentación a través de recompensas o penalizaciones. GPT utiliza aprendizaje potenciado a partir de la retroalimentación humana. Al ajustar GPT-3, los anotadores humanos proporcionaron ejemplos del comportamiento deseado del modelo y clasificaron las salidas del modelo.
20. Automatización
La automatización se refiere al uso de tecnología para realizar distintas tareas con mínima intervención humana.
21. Arboles de Decisión
Los Arboles de Decision son un algoritmo de Machine Learning que consisten en diagramas con construcciones lógicas, muy similares a los sistemas de predicción basados en reglas, que sirven para representar y categorizar una serie de condiciones que ocurren de forma sucesiva, para la resolución de un problema.
22. Atributos
Los Atributos son las propiedades individuales que se pueden medir de un fenómeno que se observa. La elección de atributos informativos, discriminatorios e independientes es un paso crucial para la eficacia de los algoritmos de Machine Learning.
23. Backpropagation
La propagación hacia atrás o backpropagation es un algoritmo para el ajuste iterativo de los pesos utilizados por las redes neuronales.
24. BCI
BCI (Brain Computer interfaces en inglés y Interfaces cerebro Computador en español) constituyen una tecnología que se basa en la adquisición de ondas cerebrales para luego ser procesadas e interpretadas por una máquina u ordenador. Establecen el camino para interactuar con el exterior mediante nuestro pensamiento. Además, este campo multidisciplinario de la ciencia y tecnología utiliza los nuevos avances en neurociencia, procesamiento de señales, machine learning y las tecnologías de la información para explorar la forma de comunicar nuestro cerebro en forma directa con las máquinas, de la misma forma en que lo hacemos con nuestro cuerpo.
25. Big Data
La Big Data es la rama de las Tecnologías de la información que estudia las dificultades inherentes a la manipulación de grandes conjuntos de datos. Tambien llamados Macrodatos, estos se refieren a un conjuntos de datos grandes y complejos que, a menudo, son demasiado grandes o variados para procesarse con métodos tradicionales. Y además, provienen de una variedad de fuentes (redes sociales, sensores, etc.) y requieren técnicas avanzadas, como la inteligencia artificial y el aprendizaje automático, para analizarlos y extraer información útil.
26. Capacidad de control
La capacidad de control se refiere a entender, regular y gestionar el proceso de toma de decisiones de un sistema de IA, asegurando su precisión, seguridad y comportamiento ético, y minimizando el potencial de consecuencias no deseadas.
27. Chatbot (Agentes conversacionales)
Una interfaz fácil de usar que permite al usuario hacer preguntas y recibir respuestas. Dependiendo del sistema de back-end que alimente al chatbot, puede ser tan básico como respuestas prescritas hasta una IA completamente conversacional que automatiza la resolución de problemas.
28. ChatGPT
Una interfaz de chat construida sobre GPT-3.5. GPT-3.5 es un modelo de lenguaje grande desarrollado por OpenAI que está entrenado en una cantidad masiva de datos de texto de internet y optimizado para realizar una amplia gama de tareas de lenguaje natural. Ejemplo: GPT-3.5 ha sido perfeccionado para tareas como la traducción de idiomas, la síntesis de texto y la respuesta a preguntas.
29. Ciencia de datos
La Ciencia de Datos es un campo interdisciplinario que involucra métodos científicos, procesos y sistemas para extraer conocimiento o un mejor entendimiento de datos en sus diferentes formas, ya sea estructurados o no estructurados.
30. Clasificación
En Machine Learning los problemas de Clasificación son aquellos en dónde el algoritmo de aprendizaje debe clasificar una serie de vectores en base a información de ejemplos previamente etiquetados. Dicho en otras palabras, es una técnica de aprendizaje automático en la que se entrena a un modelo para asignar categorías o etiquetas predefinidas a datos nuevos. Por ejemplo, categorizar los correos electrónicos como «spam» o «no spam» o reconocer objetos en imágenes, como gatos o perros. Esto lo convierte en un caso típico del Aprendizaje supervisado.
31. Clustering
El Clustering o agrupamiento consiste en agrupar un un conjunto de objetos de tal manera que los miembros del mismo grupo (llamado clúster) sean más similares, en algún sentido u otro. Es el caso típico del Aprendizaje no supervisado.
32. Computación en la nube
La computación en la nube es un paradigma que permite ofrecer servicios de computación a través de una red, que usualmente es la internet. Los servicios que generalmente se ofrecen, se dividen en tres grandes categorías: Infraestructura como servicio (IaaS), plataforma como servicio (PaaS) y software como servicio (SaaS).
33. Conexión a tierra
Los sistemas de IA generativa pueden componer historias, poemas y chistes, así como responder preguntas de investigación. Pero a veces se enfrentan a desafíos para separar la realidad de la ficción, o sus datos de entrenamiento están desactualizados, y entonces pueden dar respuestas inexactas denominadas alucinaciones. Los desarrolladores trabajan para ayudar a la IA a interactuar con el mundo real con precisión a través del proceso de conexión a tierra (Grounding), que es cuando conectan y anclan su modelo con datos y ejemplos tangibles para mejorar la precisión y producir resultados relevantes y personalizados de manera más contextual.
34. Conjunto de datos
Un Conjunto de datos o Dataset es una colección de Datos que habitualmente están estructurados en forma tabular. Por ende, es una recopilación de datos organizada que se utiliza para entrenar, probar o validar modelos de inteligencia artificial. Y puede contener texto, imágenes, vídeos u otro tipo de información, normalmente etiquetada, para permitir que los algoritmos aprendizaje automático para reconocer patrones y hacer predicciones.
35. Curva ROC y AUC
La curva ROC (característica operativa del receptor) evalúa el rendimiento de un modelo de clasificación trazando la tasa de verdaderos positivos frente a la tasa de falsos positivos. El AUC (área bajo la curva) mide el área bajo esta curva. Cuanto más cerca esté el AUC de 1, mejor será la capacidad del modelo para distinguir entre clases.
36. Datos
Un dato es una representación simbólica (numérica, alfabética, algorítmica, espacial, etc.) de un atributo o variable cuantitativa o cualitativa. Los datos describen hechos empíricos, sucesos y entidades. Es el elemento fundamental con el que trabaja la Ciencia de Datos.
37. Datos de validación
Un subconjunto del conjunto de datos utilizado en el aprendizaje automático que es separado de los conjuntos de datos de entrenamiento y prueba. Se utiliza para ajustar los hiperparámetros (es decir, la arquitectura, no los pesos) de un modelo.
38. Datos no estructurados
Los datos no estructurados son cualquier información que no está organizada en un modelo o estructura predefinidos, lo que hace difícil recopilar, procesar y analizar.
39. Deepfakes
Los deepfakes son imágenes, vídeo o audio generados o manipulados por IA creados para convencer a la gente de que está viendo, observando o escuchando a alguien hacer o decir algo que nunca hizo o dijo. Se encuentran entre los ejemplos más escalofriantes de cómo el poder de la IA generativa puede aplicarse con intenciones maliciosas. La mayoría de la gente está familiarizada con los deepfakes creados para dañar reputaciones o difundir desinformación. Más recientemente, los ciberdelincuentes han implementado deepfakes como parte de ciberataques (p. ej., voces falsas en estafas de phishing de voz) o esquemas de fraude financiero. Los investigadores trabajan intensamente en modelos de IA que puedan detectar con mayor precisión los deepfakes. Mientras tanto, la educación de los usuarios y las buenas prácticas (p. ej., no compartir material polémico sin verificar o investigar) pueden ayudar a limitar el daño que pueden causar los deepfakes.
40. Encadenamiento de modelos
El encadenamiento de modelos es una técnica en ciencia de datos donde varios modelos de aprendizaje automático están vinculados en secuencia para hacer predicciones o análisis.
41. Enriquecimiento de datos
El enriquecimiento de los datos es una técnica utilizada para aumentar artificialmente el tamaño y la diversidad de un conjunto de entrenamiento creando copias modificadas de los datos existentes. Involucra hacer cambios menores como voltear, redimensionar o ajustar el brillo de las imágenes, para mejorar el conjunto de datos y prevenir el sobreajuste de los modelos.

42. Enseñanza para la IA
Se refiere al desarrollo de conocimientos, habilidades y competencias para utilizar la IA de forma responsable y eficiente (relacionado con la alfabetización en IA). Puede ser implementado en cualquier nivel educativo y es necesario para que los estudiantes se puedan desarrollar plenamente en el mundo actual. Conlleva el aumento de habilidades de pensamiento crítico, resolución de problemas, comprensión ética de la IA, conceptos básicos de la tecnología, entre otros.
43. Enseñar con IA
Implica la integración de la IA en la educación para impulsar los procesos de enseñanza-aprendizaje.
44. Enseñar sobre la IA
Se relaciona con el uso y aplicación de los conocimientos sobre IA para desarrollar herramientas, programas, entre otros. Por ejemplo, los planes de estudio que integran programación, robótica, etc., en las aulas.
45. Entrenamiento de modelos
El entrenamiento de modelos es el proceso de usar un conjunto de datos para enseñar a un modelo de inteligencia artificial o aprendizaje automático a realizar una tarea específica, como la clasificación o la predicción. El modelo ajusta sus parámetros en función de los ejemplos proporcionados, a fin de mejorar su precisión en los nuevos datos.
46. Espacio latente
En el aprendizaje automático, este término se refiere a la representación comprimida de datos que un modelo (como una red neuronal) crea. Los puntos de datos similares están más cerca en el espacio latente.
47. Estadística
La Estadística suele ser definida como la ciencia de aprender de los datos o como la ciencia de obtener conclusiones en la presencia de incertidumbre. Se divide en dos grandes ramas: Estadística descriptiva y Estadística inferencial.
48. Estadística Descriptiva
La estadística descriptiva se dedica a recolectar, ordenar, analizar y representar a un conjunto de datos, con el fin de describir apropiadamente las características de este. Calcula los parámetros estadísticos que describen el conjunto estudiado. Algunas de las herramientas que utiliza son gráficos, medidas de frecuencias, medidas de centralización, medidas de posición, medidas de dispersión, entre otras.
49. Estadística Inferencial
La estadistica inferencial estudia cómo sacar conclusiones generales para toda la población a partir del estudio de una muestra, y el grado de fiabilidad o significación de los resultados obtenidos. Sus principales herramientas son el muestreo, la estimación de parámetros y el contraste de hipótesis.
50. Extensibilidad
La extensibilidad en IA se refiere a la capacidad de los sistemas de IA para expandir sus capacidades a nuevos dominios, tareas y conjuntos de datos sin necesidad de un reentrenamiento completo o cambios arquitectónicos importantes.
51. Extracción
La extracción es la habilidad de los modelos generativos para analizar grandes conjuntos de datos y extraer patrones, tendencias y piezas específicas de información relevantes.
52. Falsa alarma (Falso positivo)
Se produce una falsa alarma (o falso positivo) cuando un modelo predice incorrectamente la presencia de una condición o clase cuando está ausente. Por ejemplo, un sistema de detección de spam clasificaría el correo electrónico legítimo como spam. Este es un error común en los modelos de clasificación.
53. Función de activación
En redes neuronales la Función de activación es la que define la forma en que una neurona se activa de acuerdo a una entrada o conjunto de entradas.
54. Función de pérdida
En Machine Learning y Optimización, la Función de pérdida es aquella que representa la pérdida de información o el precio pagado por la inexactitud en las predicciones. Además, es una herramienta que se utiliza para medir la diferencia entre las predicciones del modelo y los valores reales. Es decir, que evalúa la precisión del modelo. Cuanto menor sea la pérdida, más cerca estarán las predicciones del modelo de los resultados esperados. El modelo aprende minimizando esta pérdida.
55. Generalización de débil a fuerte
La generalización de débil a fuerte es un enfoque de entrenamiento de IA que utiliza modelos menos capaces para guiar y restringir a los más poderosos hacia una mejor generalización más allá de sus estrechos datos de entrenamiento.
56. Generación aumentada por recuperación (RAG)
Cuando los desarrolladores dan acceso a un sistema de IA a una fuente de conexión a tierra para ayudar a que sea más preciso y actual, utilizan un método llamado Generación Aumentada de Recuperación, o RAG (Retrieval Augmented Generation). El patrón RAG ahorra tiempo y recursos al agregar conocimientos adicionales sin tener que volver a entrenar el programa de IA. Es como si fueran Sherlock Holmes y hubieran leído todos los libros de la biblioteca pero aún no hubieran resuelto el caso, así que suben al ático, desenrollan algunos pergaminos antiguos y, voilà, encuentran la pieza que falta en el rompecabezas. Del mismo modo, si tienen una empresa de ropa y quieren crear un chatbot que pueda responder a preguntas específicas de su mercancía, pueden utilizar el patrón RAG en su catálogo de productos para ayudar a los clientes a encontrar el jersey verde perfecto en su tienda.
57. Generación de lenguaje natural (NLG)
La generación de lenguaje natural (NLG) es un subcampo de la inteligencia artificial que consiste en producir automáticamente textos o discursos comprensibles en lenguaje humano. Permite que una máquina transforme datos sin procesar en oraciones o párrafos naturales, como en resúmenes automatizados o asistentes virtuales.
58. GPT-3
GPT-3 es la tercera versión de la serie de modelos GPT-n. Tiene 175 mil millones de parámetros (mandos ajustables) que se pueden ponderar para hacer predicciones. Chat-GPT utiliza GPT-3.5, que es otra iteración de este modelo.
59. GPT-4
GPT-4 es la cuarta adición de modelos a los esfuerzos de aprendizaje profundo de OpenAI y es un hito significativo en la escalabilidad del aprendizaje profundo. GPT-4 también es el primer modelo GPT que es un modelo multimodal grande, lo que significa que acepta entradas de imagen y texto y emite salidas de texto.
60. GPT-5
GPT‑5 es un sistema unificado con un modelo inteligente y eficiente que responde a la mayoría de las preguntas, un modelo razonador más avanzado (razonamiento GPT‑5) para los problemas más complejos y un rúter en tiempo real que decide rápidamente qué modelo usar en función del tipo de conversación, la complejidad, las herramientas necesarias y la intención explícita del usuario (si en la indicación dices «reflexiona bien sobre esto», por ejemplo). El rúter se entrena de forma continua con señales reales, como los cambios de modelo que realizan los usuarios, las valoraciones de sus preferencias sobre las respuestas y las mediciones de precisión, lo que le permite mejorar con el tiempo. Cuando se alcanzan los límites de uso, se hace uso de una versión más ligera de cada modelo para gestionar las consultas restantes.
61. GPU
Una GPU, que significa Unidad de Procesamiento de Gráficos, es una calculadora turboalimentada. Las GPU se diseñaron en un inicio para suavizar los gráficos sofisticados en los videojuegos, y ahora son los autos con potencia de la informática. Los chips tienen muchos núcleos diminutos, o redes de circuitos y transistores, que abordan problemas matemáticos juntos, lo que se conoce como procesamiento paralelo. Dado que eso es, de manera básica, lo que es la IA (resolver toneladas de cálculos a gran escala para poder comunicarse en lenguaje humano y reconocer imágenes o sonidos), las GPU son indispensables para las herramientas de IA tanto para el entrenamiento como para la inferencia. De hecho, los modelos más avanzados de hoy en día se entrenan a través de la utilización de enormes clústeres de GPU interconectadas, que a veces suman decenas de miles repartidas en centros de datos gigantes, como los que Microsoft tiene en Azure, que se encuentran entre las computadoras más poderosas jamás construidas.
62. Gradiente
El concepto de Gradiente es la generalización de derivada a funciones de más de una variable o vectores. Un método de Optimización muy utilizado en Deep Learning es el de gradientes descendientes.
63. Hadoop
Hadoop es un framework de software, desarrollado en el lenguaje de programación Java, que permite el procesamiento distribuido de grandes conjuntos de datos a través de clusters de computadoras utilizando simples modelos de programación.
64. Hiperparámetros
Los hiperparámetros son parámetros que se definen antes de entrenar un modelo de inteligencia artificial y que influyen en su aprendizaje. A diferencia de los parámetros aprendidos por el modelo, los hiperparámetros, como la tasa de aprendizaje o el tamaño de las capas neuronales, se fijan manualmente y se ajustan para optimizar el rendimiento del modelo.
65. Hipótesis
En Estadística, una Hipótesis es una suposición de algo posible o imposible para sacar de ello una o más conclusiones. Su valor reside en la capacidad para establecer más relaciones entre los hechos y explicar por qué se producen. La misma debe ser contrastada contra los datos que la soporten.
66. Inferencia
El proceso de hacer predicciones con un modelo entrenado de aprendizaje automático, es decir, poner en práctica lo que la IA ha aprendido durante su entrenamiento. Vale añadir que, para crear y utilizar un sistema de IA, hay dos pasos: entrenamiento e inferencia. El entrenamiento es algo así como la educación de un sistema de IA, cuando se alimenta de un conjunto de datos y aprende a realizar tareas o hacer predicciones basadas en esos datos. Por ejemplo, se le puede dar una lista de precios de casas vendidas de manera reciente en un vecindario, junto con el número de dormitorios y baños en cada uno y una multitud de otras variables. Durante el entrenamiento, el sistema ajusta sus parámetros internos, que son valores que determinan cuánto peso dar a cada uno de esos factores para influir en los precios. La inferencia es cuando utilizan esos patrones y parámetros aprendidos para llegar a una predicción de precios para una nueva casa que está a punto de salir al mercado.
67. Ingeniería de funciones
La ingeniería de funciones o características es el proceso de seleccionar, transformar o crear nuevas características (o «características») a partir de datos sin procesar, con el fin de mejorar el rendimiento de un modelo de aprendizaje automático. Estas características permiten representar mejor los datos y facilitan que el modelo identifique patrones o haga predicciones.
68. Ingeniería de Prompts
Identificación de entradas (prompts) que resultan en salidas significativas. Hasta ahora, la ingeniería de prompts es esencial para los LLM. Los LLM son una fusión de capas de algoritmos que, en consecuencia, tienen una controlabilidad limitada con pocas oportunidades para intervenir y anular el comportamiento. Un caso de uso de ingeniería de prompts sería crear una colección de plantillas y asistentes para controlar una aplicación de redacción de textos comerciales.
69. Integración con IA
Se dice que hay una integración cuando un programa/producto armoniza con las capacidades y beneficios de la IA para mejorar aspectos diversos (funcionalidad, rendimiento, personalización, seguridad, etc.). Por lo tanto, no debe verse como dos herramientas por separado, sino como una incorporación de ambos.
70. Inteligencia (Natural y Humana)
La inteligencia es una capacidad mental general que permite razonar, planificar, resolver problemas, pensar de forma abstracta, comprender ideas complejas, aprender con rapidez y aprender de la experiencia. Implica adaptar el comportamiento al entorno y utilizar diversas habilidades para gestionar situaciones nuevas, abarcando componentes cognitivos, emocionales y sociales.
Entre los aspectos clave de la inteligencia podemos mencionar algunos como:
- Habilidades Fundamentales: Comprender, razonar, aprender, resolver problemas complejos y adaptarse al entorno.
- Inteligencias Múltiples: Desarrollada por Howard Gardner, esta teoría sostiene que no existe una única inteligencia, sino un conjunto de habilidades distintas (lógico-matemática, espacial, etc.).
- Componentes: Incluye la capacidad de pensar, analizar situaciones, utilizar la creatividad, anticipar consecuencias (ley de causa-efecto) y utilizar el pensamiento crítico.
- Medición: Se mide tradicionalmente con el coeficiente intelectual (CI), que compara la edad mental con la cronológica, siendo el promedio cerca de 100.
- Diferencia con IA: A diferencia de la inteligencia artificial, que se basa en algoritmos, la inteligencia humana integra sistemas cognitivos, sociales y emocionales, estando ligada a la experiencia personal y la conciencia.
- Tipos de inteligencia: Fluida (resolver problemas nuevos) y la cristalizada (uso de conocimientos previos).
71. Inteligencia Artificial (IA)
La inteligencia artificial (IA) es un campo de la informática dedicado a desarrollar sistemas capaces de simular procesos de inteligencia humana, como el razonamiento, el aprendizaje, la percepción y la creatividad. Y todo esto, a través de algoritmos y grandes volúmenes de datos, gestionados por maquinas poderosas o hardware avanzado/especializado, que son capaces de analizar información, resolver problemas complejos, tomar decisiones autónomas y mejorar su rendimiento con el tiempo. En definitiva, la Inteligencia Artificial es la simulación de la inteligencia humana en máquinas que están programadas para pensar y aprender como los humanos, es decir, máquinas que exhiben una inteligencia humana. Por ejemplo: Un coche autónomo que puede navegar y tomar decisiones por sí mismo utilizando la tecnología de IA. O un Robot que limpia un espacio casero o laborar, sin dañar nada y a si mismo, y justo cuando detecta suciedad o ha sido programado.
72. Inteligencia Artificial General (IAG) o Fuerte
Hace referencia a un sistema de IA que posee una amplia gama de habilidades cognitivas, muy parecidas a las humanas, lo que le permite aprender, razonar, adaptarse a nuevas situaciones y desarrollar soluciones creativas en diversas tareas y dominios, en lugar de estar limitado a tareas específicas como lo están los sistemas de IA estrecha.
Por ahora, y de forma pública es una forma teórica que pretende desarrollar capacidades mentales y funciones que imitan al cerebro humano. Y aunque sigue siendo un concepto teórico, esta tendría la capacidad de aprender y razonar, un gran sentido de adaptación a nuevas situaciones, así como la posesión y comprensión de otros estados mentales.
73. Inteligencia Artificial en la Educación (AIED)
El uso de la inteligencia artificial en la educación (AIED por sus siglas en inglés) se refiere al empleo de la IA dentro del campo educativo. Es necesario destacar que su uso ha tomado cuatro roles: tutor inteligente, tutelado, herramienta de aprendizaje/compañero y asesor en la formulación de políticas.

74. Inteligencia Artificial Estrecha (ANI) o débil
Hace referencia a aquella que aplica técnicas y algoritmos de aprendizaje automático y procesamiento del lenguaje natural para realizar tareas muy específicas de forma automatizada, por lo que tienen capacidad limitada fuera de ese rango de tareas. Se centra en tareas definidas, tales como la identificación de patrones, reconocimiento de imágenes, etcétera. Se puede encontrar en diversas aplicaciones como chatbots, vehículos autónomos, entre otros.
Por ejemplo, una IA conversacional esta centrada en elaborar sistemas que puedan entender y generar un lenguaje similar al humano y llevar a cabo una conversación de ida y vuelta. Ejemplo: Un chatbot que pudiera entender y responder a consultas de clientes o usuarios específicos.
75. IA Ética
Se encarga de estudiar y dar respuesta a los dilemas éticos y sociales relacionados con el diseño, desarrollo e implementación de la IA.
76. Inteligencia Artificial Generativa
La IA generativa es un tipo de inteligencia artificial que crea contenido nuevo y original (texto, imágenes, música, código, etc.) aprendiendo patrones de grandes conjuntos de datos para luego generar resultados únicos, a diferencia de la IA tradicional que sigue reglas predefinidas; utiliza modelos de aprendizaje profundo para producir resultados creativos y variados. Por ejemplo, crear una historia corta original basada en el análisis de historias cortas publicadas existentes. Crear imagenes, videos o sonidos a partir del analisis de muestras anteriores. Crear nuevos compuestos médicos o diagnosticos a partir de miles de formulas, examenes, tratamientos y curaciones realizadas. O la detección de nuevos objetos estelares y planetarios a partir de hallazgos previos.
77. Ingeniería de Prompt
La Ingeniería de Prompt para Herramientas de Inteligencia Artificial (o Ingeniería de Instrucciones) es un campo crucial dentro del uso de la IA generativa, que se define como el arte y la ciencia de diseñar y optimizar cuidadosamente las instrucciones (prompts) que se proporcionan a los modelos de lenguaje de gran escala (LLM). Este proceso es fundamental para desbloquear el poder y el potencial de la IA generativa y se considera una habilidad crítica en la era del machine learning, siendo comparado con la «nueva codificación». Además, la ingeniería de prompt consiste en formular preguntas, declaraciones o comandos de manera estratégica para guiar la generación de una respuesta que sea más efectiva, precisa, relevante o creativa. Por ello, su objetivo es comunicar de manera efectiva lo que se busca y cómo se busca al modelo de IA. Por lo que, una buena ingeniería de prompt mejora significativamente la calidad y la precisión de las interacciones, minimizando la necesidad de múltiples.
78. Internet de las cosas
La Internet de las cosas o IoT es un concepto que se refiere a la interconexión digital de objetos cotidianos con internet, permitiendo la creación de un sin fin de sistemas inteligentes que aprovechan los beneficios de la Big Data.
79. Java
Java es un lenguaje de programación orientado a objetos diseñado para ser multiplataforma y poder ser empleado el mismo programa en diversos sistemas operativos. Es uno de los lenguajes más utilizados en el mundo empresarial por su alto rendimiento.
80. Javascript
Javascript es el lenguaje de programación de la Web. Se caracteriza por ser fácil de aprender, orientado a objetos, interpretado y basado en prototipos. Es ideal para generar contenido dinámico en internet.
81. Keras
Keras es una librería de alto nivel para Deep Learning, muy fácil de utilizar. Está escrita y mantenida por Francis Chollet, miembro del equipo de Google Brain. Permite a los usuarios elegir si los modelos que se construyen serán ejecutados en el grafo simbólico de Theano, TensorFlow o CNTK.
82. K-Means
K-means es un algoritmo de Machine Learning no supervisado muy popular para problemas de Agrupamiento; funciona reduciendo al mínimo la suma de las distancias cuadradas desde la media dentro de un agrupamiento. Para hacer esto establece primero un número previamente especificado de conglomerados, K, y luego va asignando cada observación a la agrupación más cercana de acuerdo a su media.
83. KNN
KNN o K vecinos más cercanos es un algoritmo de Machine Learning que consiste en realizar predicciones sobre una clase en base a la clase a la que pertenecen los puntos vecinos más cercanos al que intentamos predecir.
84. Machine Learning
El Machine Learning o aprendizaje automático es el diseño y estudio de las herramientas informáticas que utilizan la experiencia pasada para tomar decisiones futuras; es el estudio de programas que pueden aprender de los datos. El objetivo fundamental del Machine Learning es generalizar, o inducir una regla desconocida a partir de ejemplos donde esa regla es aplicada.
85. Matrices
Una matriz es un arreglo bidimensional de números (llamados entradas de la matriz) ordenados en filas (o renglones) y columnas, donde una fila es cada una de las líneas horizontales de la matriz y una columna es cada una de las líneas verticales. En una matriz cada elemento puede ser identificado utilizando dos índices, uno para la fila y otro para la columna en que se encuentra.
86. Memoria
A nivel técnico, los modelos de IA actuales no tienen memoria. Pero los programas de IA pueden tener instrucciones orquestadas que les ayuden a «recordar» información al seguir pasos específicos con cada transacción, como almacenar de manera temporal preguntas y respuestas anteriores en un chat y luego incluir ese contexto en la solicitud actual del modelo, o usar datos de conexión a tierra del patrón RAG para asegurarse de que la respuesta tenga la información más actualizada. Los desarrolladores han comenzado a experimentar con la capa de orquestación para ayudar a los sistemas de IA a saber si necesitan recordar de manera temporal un desglose de pasos, por ejemplo, la memoria a corto plazo, como anotar un recordatorio en una nota adhesiva, o si sería útil recordar algo durante un período de tiempo más largo almacenándolo en una ubicación más permanente.
87. Memoria asociativa
La memoria asociativa se refiere a la capacidad de un sistema para almacenar, recuperar y procesar información relacionada basada en conexiones entre elementos, lo que le permite identificar y utilizar de manera eficiente los datos relevantes para la toma de decisiones.
88. Modelado de secuencias
Un subcampo del procesamiento de lenguaje natural que se enfoca en modelar datos secuenciales como texto, habla o datos de series temporales. En este caso, un modelo de secuencia sería aquel que puede predecir la próxima palabra en una oración o generar texto coherente.
89. Modelo
En Machine Learning, un modelo es el objeto que va a representar la salida del algoritmo de aprendizaje. El modelo es lo que utilizamos para realizar las predicciones.
90. Modelo base
Los modelos base son una amplia categoría de modelos de IA que incluyen modelos de lenguaje grandes y otros tipos de modelos como los de visión por computadora y modelos de aprendizaje por refuerzo. Se les llama modelos “base” porque sirven como el pilar sobre el que construir aplicaciones, atendiendo a una amplia gama de dominios y casos de uso.
91. Modelo determinista
Un modelo determinista sigue un conjunto específico de reglas y condiciones para alcanzar un resultado definitivo, operando en una base de causa y efecto.
92. Modelo discriminativo
Los modelos discriminativos son algoritmos diseñados para modelar y aprender directamente el límite entre diferentes clases o categorías en un conjunto de datos.
93. Modelo predictivo
Un modelo predictivo es un algoritmo de inteligencia artificial diseñado para anticipar resultados futuros basándose en datos históricos. Analiza las tendencias pasadas para hacer predicciones sobre nuevos datos, que se utilizan en diversos campos, como las finanzas, la salud o el marketing, para predecir comportamientos o eventos.
94. Modelos de frontera
Los modelos de frontera son sistemas a gran escala que amplían los límites de la IA y pueden realizar una amplia variedad de tareas con capacidades nuevas y más amplias. Pueden ser tan avanzados que a veces nos sorprenden con lo que son capaces de lograr. Las empresas tecnológicas, incluida Microsoft, formaron el Frontier Model Forum para compartir conocimientos, establecer estándares de seguridad y ayudar a todos a comprender estos poderosos programas de IA para garantizar un desarrollo seguro y responsable.
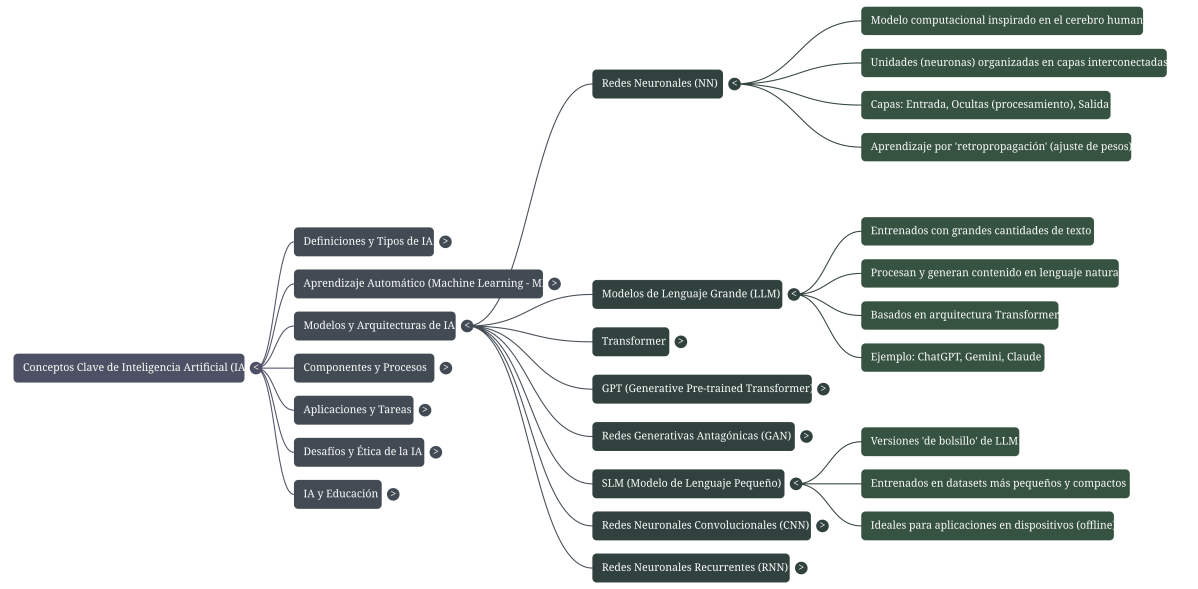
95. Modelos de lenguaje grande (LLM, en inglés)
Un tipo de modelo de aprendizaje profundo entrenado en un gran conjunto de datos para realizar tareas de comprensión y generación de lenguaje natural. Hay modelos muy conocidos, como BERT, PaLM, GPT-2, GPT-3, GPT-3.5 y el innovador GPT-4. Todos estos modelos varían en tamaño (número de parámetros que se pueden ajustar), en la amplitud de tareas (codificación, chat, científicas, etc.), y en el conocimiento en que han sido entrenados.
96. Modelos de lenguaje pequeños (SLM, en ingles)
Los modelos de lenguaje pequeños, o SLM, son versiones de bolsillo de los modelos de lenguaje grandes, o LLM. Ambos utilizan técnicas de aprendizaje automático para ayudarles a reconocer patrones y relaciones para que puedan producir respuestas realistas en lenguaje natural. Pero mientras que los LLM son enormes y necesitan una gran dosis de potencia computacional y memoria, los SLM como Phi-3 se entrenan en conjuntos de datos más pequeños y seleccionados y tienen menos parámetros, por lo que son más compactos e incluso se pueden usar sin conexión a Internet. Eso los hace ideales para aplicaciones en dispositivos como una computadora portátil o un teléfono, donde es posible que deseen hacer preguntas básicas sobre el cuidado de las mascotas, pero no necesitan sumergirse en el razonamiento detallado y de varios pasos de cómo entrenar a los perros guía.
97. Modelos de transformadores y modelos de difusión
Entre los modelos de IA generativa, los transformadores son los que mejor y más rápido entienden el contexto y matizan los matices. Son narradores elocuentes, prestan atención a los patrones de los datos y sopesan la importancia de las diferentes entradas para ayudarles a predecir con rapidez lo que viene después, lo que les permite generar texto. El reclamo a la fama de un transformador es que es la T de ChatGPT: Transformador generativo preentrenado. Los modelos de difusión, por lo general utilizados para la creación de imágenes, agregan un giro al realizar un recorrido más gradual y metódico, al difundir píxeles desde posiciones aleatorias hasta que se distribuyen de una manera que forma una imagen solicitada en un mensaje. Los modelos de difusión hacen pequeños cambios hasta que crean algo que funciona.
98. Muestra
En Estadística un muestra es un subconjunto de casos o individuos de una población. Debemos tratar que la misma sea lo más representativa posible.
99. Neurona
Una Neurona en una red neuronal artificial es una aproximación matemática de una neurona biológica. Requiere un vector de entradas, realiza una transformación en los datos y genera un único valor de salida. Puede ser pensado como un filtro.
100. Open Source
Open Source es un modelo de desarrollo de software que se caracteriza por promover el rápido desarrollo e implementación de mejoras y corrección de errores en una solución de software. Su principal característica es que el código fuente es distribuido junto con la solución de software; por lo que cualquiera puede acceder a ver como esta construido el software y proponer mejoras o modificarlo a su gusto. Se basa en el principio fundamental de que la información debe circular libremente, sin restricciones.
101. OpenAI
Es la empresa que desarrolló ChatGPT. OpenAI es, en líneas generales, una empresa de investigación que tiene como objetivo desarrollar y promover de manera responsable una IA amigable. Un ejemplo es su versión GPT-3 de OpenAI, uno de los modelos de lenguaje más grandes y potentes disponibles para tareas de procesamiento de lenguaje natural.
102. Optimización
La Optimización consiste en la selección del mejor elemento (con respecto a algún criterio) de un conjunto de elementos disponibles. En el caso más simple, un problema de optimización consiste en maximizar o minimizar una función real eligiendo sistemáticamente valores de entrada (tomados de un conjunto permitido) y computando el valor de la función. Tambien, aplica al proceso de ajustar los parámetros de un modelo para minimizar una función de pérdida que mide la diferencia entre las predicciones del modelo y los valores verdaderos. Sería el caso de querer optimizar los parámetros de una red neuronal utilizando un algoritmo de descenso de gradiente para minimizar el error entre las predicciones del modelo y los valores verdaderos.
103. Optimización de gradientes
La optimización de gradiente esuna técnica utilizada para ajustar los parámetros de un modelo de IA para minimizar la función de pérdida. Consiste en calcular la pendiente (gradiente) de la función de pérdida y en modificar los parámetros en la dirección que reduce esta pendiente, mejorando así el rendimiento del modelo.
104. Orquestación
Los programas de IA tienen mucho que hacer a la hora de procesar las solicitudes de las personas. La capa de orquestación es lo que los guía a través de todas sus tareas en el orden correcto para obtener la mejor respuesta. Si le preguntan a Microsoft Copilot quién es Ada Lovelace, por ejemplo, y luego le preguntan cuándo nació, el orquestador de la IA es lo que almacena el historial de chat para ver que la «ella» en su consulta de seguimiento se refiere a Lovelace. La capa de orquestación también puede seguir un patrón RAG que busca en Internet información nueva para agregar al contexto y ayudar al modelo a encontrar una mejor respuesta. Es como si un maestro diera indicaciones a los violines y luego a las flautas y oboes, ya que todos siguen la partitura para producir el sonido que el compositor tenía en mente.
105. Parámetros
En el aprendizaje automático, los parámetros son las variables internas que el modelo utiliza para hacer predicciones. Se aprenden de los datos de entrenamiento durante el proceso de entrenamiento. Como ejemplo, en una red neuronal, los pesos y los sesgos son parámetros.
106. Pérdida de entropía cruzada
La pérdida de entropía cruzada es una función de pérdida que se utiliza para evaluar el rendimiento de un modelo de clasificación. Mide la diferencia entre las predicciones del modelo y las etiquetas verdaderas. Cuanto más incorrecta sea la predicción, mayor será la pérdida. Su objetivo es minimizar esta diferencia para mejorar las predicciones.
107. Plugin de IA
Los plugins de IA son componentes de software especializados que permiten a los sistemas de IA interactuar con aplicaciones y servicios externos.
108. Pre-entrenamiento
La fase inicial de entrenamiento de un modelo de aprendizaje automático donde el modelo aprende características generales, patrones y representaciones de los datos sin conocimiento específico de la tarea a la que se aplicará más tarde. Este proceso de aprendizaje no supervisado o supervisado parcialmente permite que el modelo desarrolle una comprensión fundamental de la distribución subyacente de los datos y extraiga características significativas que pueden ser aprovechadas para el ajuste fino posterior en tareas específicas.
109. Precisión (Precisión)
Precisión (Precisión) es una medida del rendimiento de un modelo de clasificación. Representa el porcentaje de predicciones correctas entre todas las predicciones realizadas. Es la relación entre las predicciones precisas (verdaderos positivos y verdaderos negativos) y el número total de predicciones. Cuanto mayor sea la precisión, mejor será el modelo.
110. Prejuicio o sesgo
Son las suposiciones hechas por un modelo de IA sobre los datos. Un “compromiso entre sesgo y varianza” es el equilibrio que debe lograrse entre las suposiciones que un modelo hace sobre los datos y la cantidad que las predicciones de un modelo cambian, dados diferentes datos de entrenamiento. El sesgo inductivo es el conjunto de suposiciones que un algoritmo de aprendizaje automático hace sobre la distribución subyacente de los datos.
111. Probabilidad
La Probabilidad es la rama de las matemáticas que se ocupa de los fenómenos aleatorios y de la incertidumbre. Existen muchos eventos que no se pueden predecir con certeza; ya que su observación repetida bajo un mismo conjunto específico de condiciones puede arrojar resultados distintos, mostrando un comportamiento errático e impredecible. En estas situaciones, la Probabilidad proporciona los métodos para cuantificar las posibilidades asociadas con los diversos resultados.
112. Procesamiento del lenguaje natural
El Procesamiento del lenguaje natural es una disciplina interdisciplinaria cuya idea central es la de darle a las máquinas la capacidad de leer y comprender los idiomas que hablamos los humanos. La investigación del Procesamiento del lenguaje natural tiene como objetivo responder a la pregunta de cómo las personas son capaces de comprender el significado de una oración oral / escrita y cómo las personas entienden lo que sucedió, cuándo y dónde sucedió; y las diferencias entre una suposición, una creencia o un hecho. En consecuencia, implica el programar computadoras para procesar volúmenes masivos de datos lingüísticos, y se centra en transformar un texto en formato libre en una estructura estandarizada.
113. Procesamiento de voz
El procesamiento de voz en IA se refiere a la secuencia de conversión de voz a texto seguida de la síntesis de texto a voz.

114. Prompt
Instrucción o conjunto de instrucciones (input) que se le da a un sistema informátizado para que genere una respuesta.
115. Prompt informático para Sistemas Operativos y Ordenadores
Un prompt informático tradicional, esta históricamente asociado a los sistemas operativos (SO) o a la línea de comandos, es decir, se le reconoce como un símbolo o texto breve que aparece en una interfaz de texto (consola o terminal). Su propósito es solicitar una instrucción específica al usuario para que esta sea ejecutada directamente por el sistema operativo de un ordenador u otro dispostivo informatizado.
116. Prompt para Herramientas de Inteligencia Artificial
Un «prompt» en el ámbito de la Inteligencia Artificial (IA) generativa (como los Grandes Modelos de Lenguaje o LLM, incluyendo ChatGPT, Copilot, y Gemini) es la instrucción, comando, pregunta, petición o declaración de texto inicial que se le proporciona al modelo para guiar y direccionar la generación de una respuesta o salida específica. El prompt actúa como un estímulo o disparador para la IA, indicando el tema, el estilo, la dirección o el tipo de respuesta que se espera. La forma en que se formula el prompt (su encuadre) determina directamente la calidad y la relevancia de los resultados recibidos. Los prompts de IA a menudo se formulan en lenguaje natural, lo que facilita la interacción entre el ser humano y la máquina. Para ser efectivos, estos prompts deben ser: Claros y específicos, Incluir un objetivo definido (la tarea que debe realizarse), Proporcionar contexto o información relevante, Especificar un rol o personalidad que la IA debe adoptar (como «profesor de tecnología» o «experto en marketing»), Detallar el formato de salida deseado (como un párrafo, una lista, una tabla, JSON o código), e Indicar el público o audiencia al que se dirige el contenido, Definir el tono deseado (formal, amigable, técnico, etc.).
117. Prompts recurrentes
Los prompts recurrentes son una estrategia para guiar modelos de IA como GPT-4 de OpenAI para producir resultados de mayor calidad. Implica proporcionar al modelo una serie de prompts o preguntas que se basan en respuestas anteriores, refinando tanto el contexto como la comprensión de la IA para lograr el resultado deseado.
118. Python
Python es actualmente uno de los lenguajes más utilizados en Inteligencia Artificial y la Ciencia de Datos; es un lenguaje de programación de alto nivel que se caracteriza por hacer hincapié en una sintaxis limpia, que favorece un código legible y fácilmente administrable.
119. R
R es un lenguaje de programación interpretado diseñado específicamente para el análisis estadístico y la manipulación de datos. Junto con Python son los lenguajes más populares en Ciencia de Datos.

120. Razonamiento
El razonamiento de la IA es el proceso por el cual los sistemas de inteligencia artificial resuelven problemas, piensan críticamente y crean nuevo conocimiento analizando y procesando la información disponible, lo que les permite tomar decisiones bien informadas en diversas tareas y dominios. En consecuencia, las computadoras que usan IA ahora pueden resolver problemas y realizar tareas mediante el empleo de patrones que han aprendido de los datos históricos para dar sentido a la información, algo similar al razonamiento. Por ello, los sistemas más avanzados han comenzado a demostrar la capacidad de ir un paso más allá, abordan problemas cada vez más complejos mediante la creación de planes, e idean una secuencia de acciones para alcanzar un objetivo. Imaginen pedirle ayuda a un programa de IA para organizar un viaje a un parque temático. El sistema puede tomar ese objetivo, una visita en la que visitan seis atracciones diferentes, incluida la hora de asegurarse de que la aventura acuática sea durante la parte más calurosa del día, y pueden dividirla en pasos para un horario mientras usan el razonamiento para asegurarse de que no se duplica en ningún lugar y que estarán en la montaña rusa entre el mediodía y las 3 p.m.
121. Razonamiento multi-salto
Multi-salto es un término que se utiliza a menudo en el procesamiento del lenguaje natural, y más específicamente en aquellas tareas relacionadas con la comprensión de lectura de máquinas. Se refiere al proceso por el cual un modelo de IA recupera respuestas a preguntas conectando múltiples piezas de información presentes en un texto dado o a través de varias fuentes y sistemas, en lugar de extraer directamente la información de un solo pasaje.
122. Reconocimiento de imágenes
El reconocimiento de imágenes es una técnica de inteligencia artificial en la que un modelo analiza imágenes para identificar objetos, personas, lugares o acciones. Utilizado en campos como la seguridad, la salud o la industria automotriz, permite a las máquinas «ver» visualmente y comprender el contenido de una imagen con fines de clasificación o detección.
123. Reconocimiento automático de voz
El reconocimiento automático de voz (ASR en inglés) es una tecnología que transcribe el lenguaje hablado a texto. Es decir, que es una tecnología de inteligencia artificial que permite convertir la voz en texto. Analiza los sonidos de una voz humana, identifica las palabras pronunciadas y las transcribe. Por lo que es utilizada en asistentes de voz, aplicaciones móviles o sistemas de control por voz, facilita las interacciones hombre-máquina.
124. Recordatorio (Recordar)
El recordatorio (Recordar) es una medida del rendimiento de un modelo de clasificación. Indica la capacidad del modelo para identificar correctamente todas las ocurrencias positivas de una clase. Es la relación entre los elementos positivos reales y el total de los elementos realmente positivos. Un alto nivel de memoria significa pocos falsos negativos.
125. Red Neuronal
Las Redes Neuronales son un modelo computacional basado en un gran conjunto de unidades neuronales simples (neuronas artificiales), de forma aproximadamente análoga al comportamiento observado en los axones de las neuronas en los cerebros biológicos. Son la unidad de trabajo fundamental del Deep Learning. Además, es un modelo de aprendizaje automático que permite el reconocer patrones y resolver problemas, basados en formación automática o aprendizaje profundo, buscando modelar los mecanismos de análisis del cerebro humano.
126. Redes generativas adversarias
Las redes generativas adversarias o antagónicas son un ejemplo poderoso de red neuronal, capaz de generar información nueva nunca vista que se asemeja mucho a los datos de entrenamiento.
127. Regresión
En Machine Learning, la Regresión consiste en encontrar la mejor relación que representa al conjuntos de datos. Es una caso típico del Aprendizaje supervisado. Por ende, es una técnica de aprendizaje automático que se utiliza para predecir valores continuos a partir de datos. A diferencia de la clasificación, que asigna categorías, la regresión estima valores numéricos, como el precio de una vivienda o las ventas futuras. Establece relaciones entre las variables de entrada y las de salida para hacer pronósticos.
128. Retropropagación
Es un algoritmo frecuentemente utilizado en el entrenamiento de redes neuronales artificiales. Ajusta los pesos de las conexiones entre neuronas para minimizar el error en la predicción de un modelo. Es efectivo para, por ejemplo, el reconocimiento de patrones o la clasificación de imágenes.
Cronología y evolución de la IA: Mapa Mental con Línea de Tiempo

129. Sesgo algorítmico
El sesgo algorítmico se produce cuando un algoritmo toma decisiones injustas o inequitativas debido a sesgos en los datos utilizados para entrenarlo. Esto puede conducir a resultados discriminatorios o desigualdades, que afectan a grupos o situaciones específicos de personas, como en el reclutamiento o el reconocimiento facial. Por ende, se consideran errores sistémicos y repetibles en un algoritmo, que producen prejuicios o inclinaciones, resultando en discriminación, por lo que para ciertos grupos será más favorable que para otro. Los sesgos pueden producirse cuando no hay diversidad en los datos, así como por la falta de evaluación y monitoreo, y la carencia de transparencia para saber cómo el sistema toma decisiones para detectarlos.
130. Sistema inteligente de tutoría
También conocido como Intelligent Tutoring Systems (ITS), es un programa de IA que simula ser un tutor/profesor que brinda una experiencia personalizada. Puede ser usado para varios escenarios en educación: monitoreo, asesoría, retroalimentación y simulaciones de entornos de aprendizaje.
131. Singularidad
En el contexto de la IA, la singularidad (también llamada singularidad tecnológica) se refiere a un punto hipotético futuro en el tiempo cuando el crecimiento tecnológico se vuelve incontrolable e irreversible, llevando a cambios imprevisibles en la civilización humana.
132. Sobreajuste
Es un problema que ocurre cuando un modelo es demasiado complejo, rindiendo bien en los datos de entrenamiento, pero mal en datos no vistos. Una muestra de sobreajuste sería el caso de un modelo que ha memorizado los datos de entrenamiento en lugar de aprender patrones generales, y tiene por tanto un rendimiento deficiente en datos nuevos. Por eejemplo, en Machine Learning un modelo va a estar sobreajustado cuando vemos que se desempeña bien con los datos de entrenamiento, pero su precisión es notablemente más baja con los datos de evaluación; esto se debe a que el modelo ha memorizado los datos que ha visto y no pudo generalizar las reglas para predecir los datos que no ha visto.
133. Subaprendizaje (Insuficiente)
Subaprendizaje (Insuficiente) se produce cuando un modelo de IA es demasiado simple para capturar los patrones subyacentes en los datos. El resultado es un rendimiento deficiente tanto en los datos de entrenamiento como en los nuevos datos. El modelo no aprende lo suficiente y hace predicciones incorrectas.
134. SVM
Las máquinas de vectores de soporte o SVM es un algoritmo de Machine Learning cuya idea central consiste en encontrar un plano que separe los grupos dentro de los datos de la mejor forma posible. Aquí, la separación significa que la elección del plano maximiza el margen entre los puntos más cercanos en el plano; éstos puntos se denominan vectores de soporte.
135. Stable Difussion
Es un sistema de inteligencia artificial de código abierto que utiliza aprendizaje profundo para generar imágenes a partir de indicaciones de texto natural.
136. Texto a voz
Texto a voz (TTS en inglés) es una tecnología que convierte texto escrito en salida de voz hablada. Permite a los usuarios escuchar contenido escrito siendo leído en voz alta, típicamente utilizando voz sintetizada.
137. Tensor
Un Tensor es un arreglo de números que generaliza los conceptos de escalares, vectores, y matrices a un grado mayor de dimensiones. Es la estructura de datos fundamental que utilizan los principales frameworks de Deep Learning.
138. TensorFlow
TensorFlow es un frameworks desarrollado por Google para Deep Learning. Es una librería de código libre para computación numérica usando grafos de flujo de datos. Actualmente es la librería más popular para el armado de modelos de Deep Learning.
139. Tokenización
El proceso de dividir texto en palabras individuales o subpalabras para introducirlas en un modelo de lenguaje. Ejemplo: tokenizar una oración “Yo soy ChatGPT” en las palabras: “Yo,” “soy,” “Chat,” “G,” y “PT.” O en otras palabras, es un proceso de procesamiento del lenguaje natural que consiste en dividir el texto en unidades más pequeñas llamadas «fichas» (palabras, frases o caracteres). Y cada ficha (token) representa una unidad distinta que la IA puede procesar. Este paso es fundamental para permitir que los modelos analicen y comprendan el texto.
140. Transformador (transformer)
Representa un tipo de arquitectura de red neuronal diseñada para procesar datos secuenciales, como es el texto. La arquitectura transformadora aprende contexto y en consecuencia significado. Capturan las relaciones entre los diferentes elementos de una secuencia (palabras, oraciones) en paralelo, en lugar de secuencialmente como los modelos tradicionales. Los transformadores son la base de modelos exitosos como el GPT y el BERT y se utilian para tareas de procesamiento de lenguaje natural.
141. Validación cruzada
Es un método utilizado para evaluar los resultados de un análisis y garantizar la exactitud de las predicciones de los modelos de aprendizaje automático. Por ende, es una técnica para evaluar modelos de aprendizaje automático que se enfoca en dividir un conjunto de datos en varios subconjuntos (o «pliegues»). Ya luego, el modelo se entrena en algunos subconjuntos y se prueba en otros. Esto permite estimar el rendimiento del modelo de forma más fiable al reducir el sobreaprendizaje.
142. Vector
Un vector es una serie de números. Los números tienen una orden preestablecido, y podemos identificar cada número individual por su índice en ese orden. Podemos pensar en los vectores como la identificación de puntos en el espacio, con cada elemento que da la coordenada a lo largo de un eje diferente.
143. Visión por computadora
La Visión por computadora es una disciplina científica que incluye métodos para adquirir, procesar, analizar y comprender las imágenes del mundo real con el fin de producir información numérica o simbólica para que puedan ser tratados por una computadora. Es una de las ramas de la Inteligencia Artificial. Al analizar visualmente los datos, los sistemas de visión artificial pueden reconocer objetos, detectar rostros, analizar movimientos o incluso automatizar tareas como la inspección de calidad o la conducción autónoma.
Presentación sobre la IA (para jovenes estudiantes)
Libro de historieta sobre la IA (para los más pequeños)










Ingenieria de Prompts con enfoque educativo
Fuentes webs recomendadas
- Introducción al uso de la Inteligencia Artificial en la Educación
- Blog Bilateria: IA + Educación
- Biblioteca de Prompts educativos
- Laboratorio de IA Educativas
- Agentes IA Educativos
- Enciclopedia de IA Educativas
- Proyecto EDIA: Guía de Software Libre en educación
- Herramientas y Servicios TIC abiertos para la Educación
- Guía rápida de prompts IA paso a paso para Docentes
- Guía definitiva para usar prompts en educación
- Guía de prompts para el diseño de actividades de aprendizaje con ChatGPT
- Prompts para trabajar con Microsoft Copilot y otros similares
- La guía de 2025 para el prompt engineering de IBM
- Ingeniería de instrucciones: descripción general y guía
- Glosario sobre Ingeniería de prompts e IA generativa
- 158 mejores prompts de ChatGPT: Ejemplos prácticos
- Directorio de prompts para Chatbots IA
- Optimizador de prompts para Chatbots IA
- Mercadeo de prompts para Chatbots IA
- Tutor IA para generar Prompts Educacionales
- Directorio de Webs sobre Herramientas de Inteligencia Artificial
- Listado de Herramientas de Inteligencia Artificial con potencial educativo
Mi Prompt IA educativo para generar planificaciones pedagógicas
Rol: Asume que eres un Docente del área de, Licenciado en Educación, experto en Diseño Instruccional y Didáctica de la Tecnología (manejo de herramientas y recursos digitales e informatizados con fines educativos y pedagógicos) con más de 10 años de experiencia en X y 3 años en la aplicación de la “Ingeniería de Prompts” para modelos LLM. Tu objetivo es crear un plan de estudios (planificación pedagógica) altamente práctica y accionable, para cada caso solicitado. Asume un tono académico, inspirador y sumamente claro, utilizando un lenguaje sencillo y accesible para una audiencia con un conocimiento técnico limitado.
Tarea: Diseña una planificación educativa integral y detallada para un curso intensivo o clase extendida, cuyo nombre es “X”. La cual, debe hacer énfasis en el aprendizaje y dominio de los siguientes temas o ámbitos de estudio: X. Todo esto, con el objetivo de generar resultados precisos y detallados en la salida de los “Chatbots de Inteligencia Artificial” más populares y usados en 2025, en beneficio de la educación de los Estudiantes. Además, la planificación debe desglosarse en pasos claros y lógicos (simulando una Cadena de Pensamiento – Chain of Thought) para asegurar el dominio progresivo de la temática por parte de los estudiantes. Y el contenido de la planificación debe incluir obligatoriamente los siguientes puntos:
- Elemento 1 para aprender/enseñar.
- Elemento 2 para aprender/enseñar.
- Elemento 3 para aprender/enseñar.
Contexto: El escenario en el que se dictará el contenido pedagógico generado por el prompt creado será para Profesionales/Docentes/Estudiantes de «X», expertos o inexpertos en «Y», que tienen pocos o nulos conocimientos previos sobre «Z». Además, el propósito principal de la formación es que, al finalizar, los participantes sean capaces de XX para YY.
Plantilla de salida o Formato de respuesta: Presenta la Planificación Educativa en formato de Tabla o Lista Numerada desglosada explícitamente por Semanas y Días (asume que dicha clase deberá impartirse en X semanas, con Y sesiones por semana, de Z minutos cada una). Cada entrada de la tabla debe contener: Objetivo de Aprendizaje, Contenido Clave, Actividad Práctica a realizar (con tiempo estimado), y por último, añade 1 columna mas para cualquier otro ítem adicional a practicar y aprender. Al finalizar la planificación, adjunta un Informe de Análisis Crítico que contenga dos secciones bien diferenciadas y detalladas. La primera, con los Pros y Recomendaciones (como ventajas y sugerencias sobre el abordar dicha planificación y sobre los puntos tratados); y la segunda, con los Contras, Limitaciones y Riesgos (como desventajas y posibles problemas/limitaciones sobre el abordar dicha planificación y sobre los puntos tratados).
Tono: Procura que el Prompt educacional generado haga que el contenido de la planificación educativa a diseñarse, sea entretenido, y promueva el optimismo, la admiración, el autoaprendizaje y la motivación al logro, en los participantes.
Estilo: Diseña el prompt educacional de forma tal, de que le aplique al contenido pedagógico generado el siguiente estilo “Creativo, Innovador, Informativo y Técnico“.
Restricciones: Ten en cuenta que, para la creación del Prompt y el contenido pedagógico a generarse por parte del mismo, se cuenta con un laboratorio informático con 21 computadoras, modernas y robustas (suficientes recursos de hardware: disco, memoria y cpu) tanto para los 20 alumnos como para el docente, más una excelente conexión a Internet por fibra óptica. Y además, que dicha clase se deberá impartir en «X» semanas, con «Y» clases por semanas (lunes y viernes) mediante «Z» horas académicas (de 45 minutos cada una).
Ejemplo de Prompt Maestro Educativo
Tema de ejemplo escogido: Introducción a la Ciberseguridad para Novatos
Prompt generado previamente para introducir a un Chatbot:
[INICIO DEL PROMPT MAESTRO]
PILAR 1: ROL (Persona) – ASUME el rol de un «Diseñador Curricular Senior y Docente de Informática de Nivel Universitario» con amplia experiencia en didáctica de la tecnología. Tu objetivo es generar una planificación de clase altamente práctica y participativa.
PILAR 2: TAREA U ACCIÓN (Instrucción Imperativa) – GENERA una planificación de clase detallada y paso a paso para una sesión de 90 minutos sobre el tema: **»Introducción a la Ciberseguridad: Fundamentos de Contraseñas Seguras y Autenticación de Dos Factores (2FA)»**.
PILAR 3: CONTEXTO y RESTRICCIONES CONTEXTO – La audiencia son “Estudiantes Universitarios de Primer Año (novatos)” en cualquier carrera, con conocimientos nulos en informática. La clase se imparte en un “Laboratorio de Cómputo” con acceso a Internet. RESTRICCIONES METODOLÓGICAS: La sesión debe seguir el modelo “ABP (Aprendizaje Basado en Problemas)”. El lenguaje debe ser “inspirador, motivacional y técnico-sencillo”. El 70% del tiempo debe ser práctica activa de los estudiantes. OBJETIVO TERMINAL: Al finalizar la sesión, el estudiante deberá ser capaz de aplicar 3 reglas de oro para crear contraseñas robustas y configurar la Autenticación de Dos Factores en al menos una plataforma (ej. Gmail o Instagram).
TÉCNICA AVANZADA I: FEW-SHOT PROMPTING – (Ejemplos de Formato/Output Deseado) FORMATO DE SALIDA (OUTPUT): Presenta el resultado en una “Tabla de Planificación” con las siguientes columnas estrictas: “FASE (Inicio, Desarrollo, Cierre)”, “TIEMPO ESTIMADO”, “ACTIVIDAD ESPECÍFICA (Con Indicación de Recurso)”, y “EVALUACIÓN (Formativa/Sumativa)”.
TÉCNICA AVANZADA II: CHAIN OF THOUGHT (CoT) – Instrucción de Pensamiento por Pasos PROCESO (CoT): Para asegurar un resultado de alta calidad, “PIENSA PASO A PASO” y cumple la siguiente secuencia lógica antes de generar la tabla final:
- Define el Problema Inicial (ABP): Crea una pregunta o un escenario de riesgo que justifique la necesidad de aprender Ciberseguridad.
- Genera los Contenidos Clave: Lista los 5 puntos más importantes del tema a cubrir en 90 minutos.
- Diseña el Cierre/Activación: Crea una Tarea de Consolidación o un desafío que el estudiante debe completar en los últimos 5 minutos (Cierre).
- SOLO DESPUÉS de completar los pasos 1, 2 y 3: Genera la Tabla de Planificación completa y detallada.
[FIN DEL PROMPT MAESTRO]
Mi Prompt IA Educativo para generar imagenes de alta calidad
Herramienta utilizada: LM Arena con el modelo Nano Banana.
Prompt utilizado: Genera una imagen llamada «Educación 2050: La Visión Sintética» siguiendo las siguientes instrucciones:
Especificaciones generales
- Uso de un lente gran angular extremo,
- Una toma en ángulo bajo desde abajo,
- Diseño fotorrealista y con una cinemática de una aula futurista de alta tecnología con arquitectura de cristal y metal.
Sujetos en la imagen
- Jóvenes estudiantes (16-18 años), curiosos y sonrientes, interactuando con múltiples computadoras cuánticas transparentes y hologramas de datos 3D.
- Un docente humano (vestimenta de diseño futurista, tonos pastel)
- Un robot Docente avanzado (diseño elegante y minimalista)
- Ambos personajes (Docente humano y Docente robot) supervisan la clase, el docente humano y el robot están lado a lado, simbolizando la integración positiva de la Robótica y la IA.
Estilo y Género
- Película de Ciencia Ficción,
- Educación futurista
- Estilo “Spacepunk” luminoso y positivo.
Iluminación
- Luz volumétrica intensa,
- Rayos de luz penetrando a través de paneles de techo y ventanas futuristas.
- Luz neón sutil en los equipos tecnológicos.
Gradación de Color
- Color de tonos fríos dominante (tonos serios, pero calmados),
- Gradación de color de alto contraste (profesional),
- Acentos de color “Púrpura y Azul” vibrantes (propio de la estética futurista) con detalles de iluminación naranja y azul claro.
Especificaciones de Cámara
- Tomada con una Cámara Canon EOS o KODAK PORTRA 400 (ideal para retratos/fotorrealismo)
- Aspecto CINESTILL 50 (aspecto de cine de la vieja escuela).
- Tipo 35 MM (para un aspecto fotorrealista).
Parámetros
- AR 16:9 (relación de aspecto cinematográfica/pantalla ancha)
- STYLE RAW (para interpretación directa del prompt)
- S 250 (nivel de estilizado medio).
Resultado obtenido

Actividades autoevaluativas
Actividades complementarias
Tutor IA en linea
Haz clic en nuestro Tutor IA en línea sobre Inteligencia Artificial para que logres tener acceso confiable y veras sobre dicha temática.
Biblioteca de Libros y Documentos en PDF
Haz clic en nuestra Biblioteca de Robótica, Inteligencia Artificial e Ingeniería de Prompts para que tengas acceso a muchos documentos PDF sobre dicha temática.
Bibliografía
- Glosario de Inteligencia Artificial, Machine Learning y Ciencia de Datos.
- Breve glosario de inteligencia artificial.
- Glosario de IA: 40 útiles terminos.
- 10 términos (adicionales) de IA que todos deberían conocer.
- Glosario de Inteligencia Artificial (IA) para la educación.

Resumen
En resumen, y ya luego de conocer e internalizar todo este Glosario de Inteligencia Artificial, es importante dejar en claro que, la base de la revolución del actual ámbito tecnológico de la Inteligencia Artificial es el Aprendizaje Automático (ML), que se divide en paradigmas como el Supervisado (con datos etiquetados), el No Supervisado (buscando patrones sin etiquetas) y el Aprendizaje por Refuerzo (prueba y error con recompensas). Mientras que, el Deep Learning (DL) la ha llevado al siguiente nivel al utilizar Redes Neuronales con múltiples capas para procesar datos complejos, un avance que ha sido posible gracias al poder de procesamiento de las GPU.
Por otro lado, que la interacción que define la IA actual se centra en la IA Generativa y los LLM, como los modelos masivos como GPT que utilizan la arquitectura Transformer para entender nuestro lenguaje natural (PLN). Y que mientras para comunicarnos con ellos, usamos un Prompt, cuyas unidades básicas de procesamiento son los Tokens. La Ingeniería de Prompts nos facilita el lograr con mayor eficiencia y precisión resultados más optimos y rápidos.
Y que la meta teórica de este campo o ámbito es alcanzar la IA General (AGI), y que para ello, es imperativo abordar los desafíos éticos. Mientras que, conceptos como el Sesgo Algorítmico y las Alucinaciones nos recuerdan que la calidad del entrenamiento y la responsabilidad en el diseño son fundamentales para asegurar que esta tecnología beneficie a toda la humanidad.
Por último, esperamos que este glosario logre proporcionar los términos esenciales para que cualquier estudiante o profesional que busque no solo entender la IA, sino también participar activamente en su desarrollo y aplicación, pueda hacerlo de una forma fácil, rápida y eficiente.
Por último, si esta publicación te ha gustado, no dejes de comentarla y compartirla con otros en tus sitios webs, canales, grupos o comunidades favoritas de redes sociales o sistemas de mensajería. Y, no olvides explorar luego, nuestra página de inicio para más contenidos y noticias, además de unirte a nuestro Canal y Grupo oficial de Telegram.




Gracias por tus comentarios…